kaggleを試してみた
最近機械学習の勉強をはじめました。何冊か本を購入しザーッと目を通し(深くは理解できてません)、次に何か適当なサンプルで機械学習を試してみようと思いましたが、なかなか都合が良いデータというのはないです。
そんな時にKaggleを見つけました。Kaggleはデータ分析コンペを行うサイトですが、機械学習を勉強するのにも、すごく役立つサイトです。
「Titanic: Machine Learning from Disaster」という学習用のコンペをチュートリアルで最初にやるようになってますが、すでに日本語でたくさん紹介されてるので「House Prices: Advanced Regression Techniques」というのをやってみます。タイタニックが分類に対してこれは回帰の問題です。
やってみる、といっても初心者には何からやるのか検討がつきませんが、Kaggleには多くの方々が自分が行ったコード等(Kernels)を説明付きで公開してくれているので、それらを真似すればできます。
最初は人が作ったKernelsをひたすら見て自分のものにする、という感じかと思います。
以下も基本、人が作ったKernelsを参考に書いてます。
また、Kaggleには開発環境もあり、スクリプトまたはノートブック(Jupyter Notebook)の形式でブラウザから試すことできます。システムとしてよくできていると思います。
目的
アイオワ州のエイムズにある住宅価格を79の特徴量より予測します。Ames Housing dataset
データの前処理
ライブラリを読み込みます。
import pandas as pd import numpy as np import seaborn as sns import matplotlib import matplotlib.pyplot as plt from scipy.stats import skew from scipy.stats.stats import pearsonr %config InlineBackend.figure_format = 'retina' #set 'png' here when working on notebook %matplotlib inline
データを確認してみます。
train = pd.read_csv("../input/train.csv")
test = pd.read_csv("../input/test.csv")
train.head()
| Id | MSSubClass | MSZoning | LotFrontage | LotArea | Street | Alley | LotShape | LandContour | Utilities | LotConfig | LandSlope | Neighborhood | Condition1 | Condition2 | BldgType | HouseStyle | OverallQual | OverallCond | YearBuilt | YearRemodAdd | RoofStyle | RoofMatl | Exterior1st | Exterior2nd | MasVnrType | MasVnrArea | ExterQual | ExterCond | Foundation | BsmtQual | BsmtCond | BsmtExposure | BsmtFinType1 | BsmtFinSF1 | BsmtFinType2 | BsmtFinSF2 | BsmtUnfSF | TotalBsmtSF | Heating | … | CentralAir | Electrical | 1stFlrSF | 2ndFlrSF | LowQualFinSF | GrLivArea | BsmtFullBath | BsmtHalfBath | FullBath | HalfBath | BedroomAbvGr | KitchenAbvGr | KitchenQual | TotRmsAbvGrd | Functional | Fireplaces | FireplaceQu | GarageType | GarageYrBlt | GarageFinish | GarageCars | GarageArea | GarageQual | GarageCond | PavedDrive | WoodDeckSF | OpenPorchSF | EnclosedPorch | 3SsnPorch | ScreenPorch | PoolArea | PoolQC | Fence | MiscFeature | MiscVal | MoSold | YrSold | SaleType | SaleCondition | SalePrice | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 60 | RL | 65.0 | 8450 | Pave | NaN | Reg | Lvl | AllPub | Inside | Gtl | CollgCr | Norm | Norm | 1Fam | 2Story | 7 | 5 | 2003 | 2003 | Gable | CompShg | VinylSd | VinylSd | BrkFace | 196.0 | Gd | TA | PConc | Gd | TA | No | GLQ | 706 | Unf | 0 | 150 | 856 | GasA | … | Y | SBrkr | 856 | 854 | 0 | 1710 | 1 | 0 | 2 | 1 | 3 | 1 | Gd | 8 | Typ | 0 | NaN | Attchd | 2003.0 | RFn | 2 | 548 | TA | TA | Y | 0 | 61 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | 0 | 2 | 2008 | WD | Normal | 208500 |
| 1 | 2 | 20 | RL | 80.0 | 9600 | Pave | NaN | Reg | Lvl | AllPub | FR2 | Gtl | Veenker | Feedr | Norm | 1Fam | 1Story | 6 | 8 | 1976 | 1976 | Gable | CompShg | MetalSd | MetalSd | None | 0.0 | TA | TA | CBlock | Gd | TA | Gd | ALQ | 978 | Unf | 0 | 284 | 1262 | GasA | … | Y | SBrkr | 1262 | 0 | 0 | 1262 | 0 | 1 | 2 | 0 | 3 | 1 | TA | 6 | Typ | 1 | TA | Attchd | 1976.0 | RFn | 2 | 460 | TA | TA | Y | 298 | 0 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | 0 | 5 | 2007 | WD | Normal | 181500 |
| 2 | 3 | 60 | RL | 68.0 | 11250 | Pave | NaN | IR1 | Lvl | AllPub | Inside | Gtl | CollgCr | Norm | Norm | 1Fam | 2Story | 7 | 5 | 2001 | 2002 | Gable | CompShg | VinylSd | VinylSd | BrkFace | 162.0 | Gd | TA | PConc | Gd | TA | Mn | GLQ | 486 | Unf | 0 | 434 | 920 | GasA | … | Y | SBrkr | 920 | 866 | 0 | 1786 | 1 | 0 | 2 | 1 | 3 | 1 | Gd | 6 | Typ | 1 | TA | Attchd | 2001.0 | RFn | 2 | 608 | TA | TA | Y | 0 | 42 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | 0 | 9 | 2008 | WD | Normal | 223500 |
| 3 | 4 | 70 | RL | 60.0 | 9550 | Pave | NaN | IR1 | Lvl | AllPub | Corner | Gtl | Crawfor | Norm | Norm | 1Fam | 2Story | 7 | 5 | 1915 | 1970 | Gable | CompShg | Wd Sdng | Wd Shng | None | 0.0 | TA | TA | BrkTil | TA | Gd | No | ALQ | 216 | Unf | 0 | 540 | 756 | GasA | … | Y | SBrkr | 961 | 756 | 0 | 1717 | 1 | 0 | 1 | 0 | 3 | 1 | Gd | 7 | Typ | 1 | Gd | Detchd | 1998.0 | Unf | 3 | 642 | TA | TA | Y | 0 | 35 | 272 | 0 | 0 | 0 | NaN | NaN | NaN | 0 | 2 | 2006 | WD | Abnorml | 140000 |
| 4 | 5 | 60 | RL | 84.0 | 14260 | Pave | NaN | IR1 | Lvl | AllPub | FR2 | Gtl | NoRidge | Norm | Norm | 1Fam | 2Story | 8 | 5 | 2000 | 2000 | Gable | CompShg | VinylSd | VinylSd | BrkFace | 350.0 | Gd | TA | PConc | Gd | TA | Av | GLQ | 655 | Unf | 0 | 490 | 1145 | GasA | … | Y | SBrkr | 1145 | 1053 | 0 | 2198 | 1 | 0 | 2 | 1 | 4 | 1 | Gd | 9 | Typ | 1 | TA | Attchd | 2000.0 | RFn | 3 | 836 | TA | TA | Y | 192 | 84 | 0 | 0 | 0 | 0 | NaN | NaN | NaN | 0 | 12 | 2008 | WD | Normal | 250000 |
データの変換
ほとんどのモデルは特徴量及び出力がガウス分布に従っている方がうまくいきます。ヒストグラムが左右対称の「ベルカーブ」になるように、特徴量及び出力にlogを適用します。
matplotlib.rcParams['figure.figsize'] = (12.0, 6.0)
prices = pd.DataFrame({"price":train["SalePrice"], "log(price + 1)":np.log1p(train["SalePrice"])})
prices.hist()
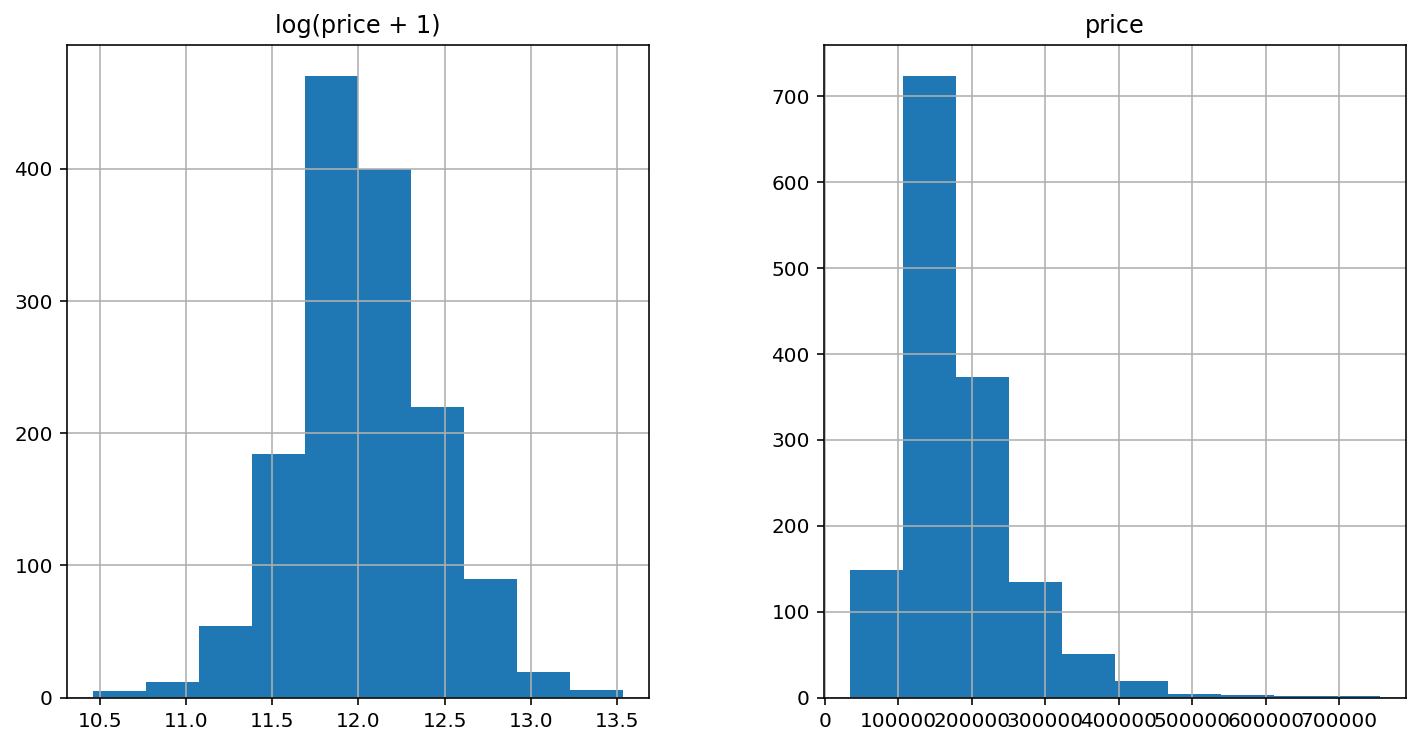
出力「SalePrice」はlog(price + 1)で、歪度がだいぶ減りました。1を足してるのは、データに値 0 があるので(そして対数 は0に対して定義できないので)、直接logを使うことはできないためです。
train["SalePrice"] = np.log1p(train["SalePrice"])
特徴量で、数値でかつ歪度が大きい場合のみ同様の変換を行います。
all_data = pd.concat((train.loc[:,'MSSubClass':'SaleCondition'],
test.loc[:,'MSSubClass':'SaleCondition']))
# 数値のみ
numeric_feats = all_data.dtypes[all_data.dtypes != "object"].index
# 欠損値NaNを除外後、歪度を計算
skewed_feats = train[numeric_feats].apply(lambda x: skew(x.dropna()))
skewed_feats = skewed_feats[skewed_feats > 0.75]
skewed_feats = skewed_feats.index
all_data[skewed_feats] = np.log1p(all_data[skewed_feats])
カテゴリ変数の変換
特徴量がカテゴリ文字列のデータを、回帰で扱えるようするため数値に変換します。ワンホットエンコー ディングという方法を使い、カテゴリ変数を1つ以上の0と1の値を持つ新しい特徴量で置き換えます。
たとえばGarageQualという特徴量は、Ex(Excellent)、Gd(Good)、TA(Typical/Average)、Fa(Fair)、Po(Poor)、NA(No Garage)のいづれかの値を持ちますが、新たに以下の0または1の値を持つ特徴量を作ります。
GarageQual_Ex、GarageQual_Gd、GarageQual_TA、GarageQual_Fa、GarageQual_Po、GarageQual_NA。
というのを以下の一行でやってくれます。
all_data = pd.get_dummies(all_data)
欠損値を平均値で埋める
all_data = all_data.fillna(all_data.mean())
モデル作成
特徴量の中にはあまり重要でないものがあるようなので、L1正則化を行うLasso回帰でモデルを作ります。L1正則化を行うと、いくつかの係数は無視されます。
X_train = all_data[:train.shape[0]] X_test = all_data[train.shape[0]:] y = train.SalePrice from sklearn.linear_model import Lasso model_lasso = Lasso() scores = cross_val_score(model_lasso, X_train, y) # 交差検証で評価 scores.mean()
0.54583131173476207
デフォルトだとスコア低いです。Lassoのパラメータalphaをいろいろ変えて最適な値を見つけます。
というのを、交差検証を用いて最適なalphaを探してくれるLassoCVがやってくれます。
from sklearn.linear_model import LassoCV model_lasso = LassoCV(alphas = [1, 0.1, 0.001, 0.0005]).fit(X_train, y) scores = cross_val_score(model_lasso, X_train, y) # 交差検証で評価 scores.mean()
0.90117979437604168
どの特徴量が影響を及ぼしているか確認してみます。
coef = pd.Series(model_lasso.coef_, index = X_train.columns)
imp_coef = pd.concat([coef.sort_values().head(10),
coef.sort_values().tail(10)])
matplotlib.rcParams['figure.figsize'] = (8.0, 10.0)
imp_coef.plot(kind = "barh")
plt.title("Coefficients in the Lasso Model")
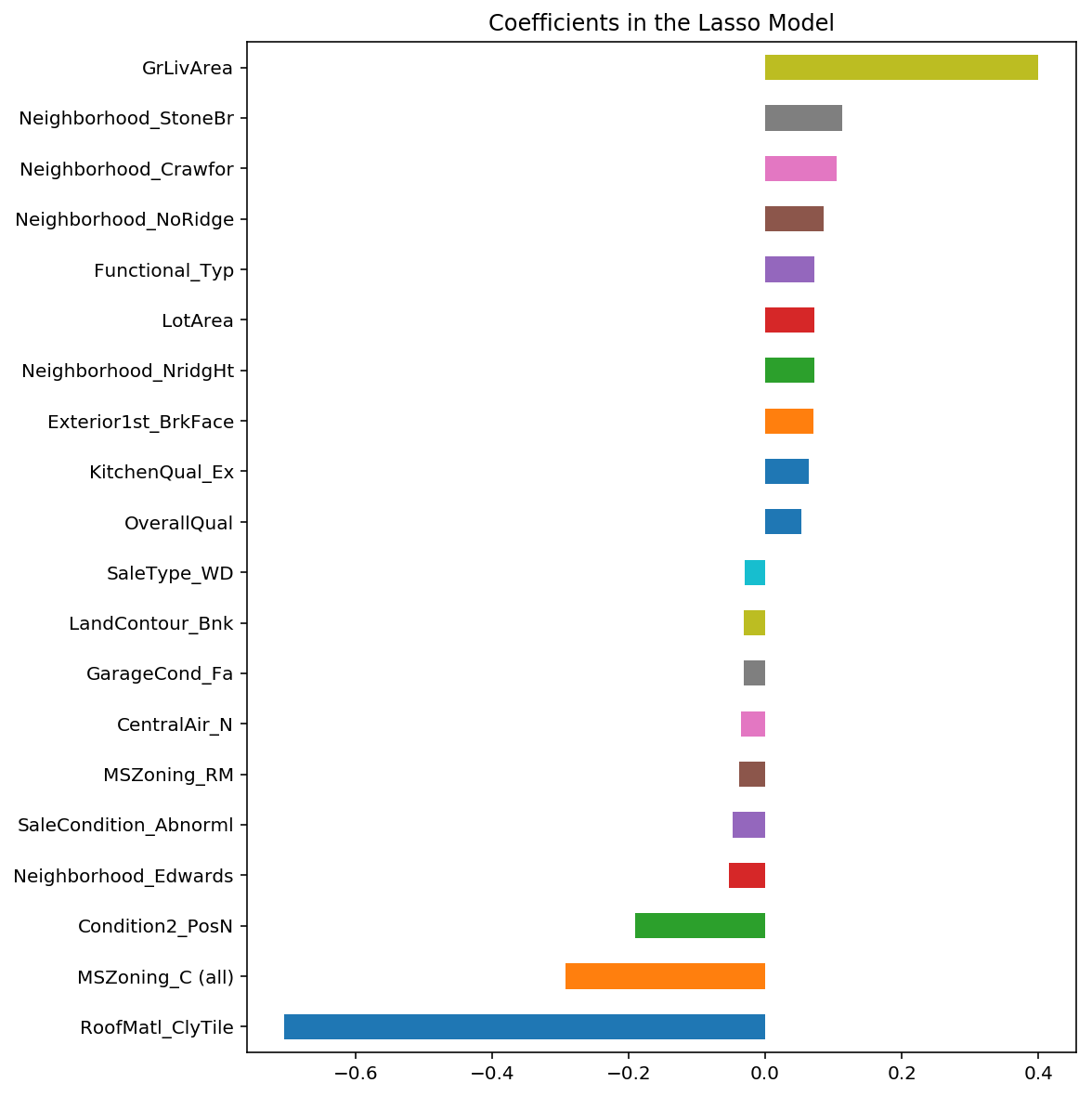
GrLivAreaとは、地上の建物面積です。
Above grade (ground) living area square feet
テストデータを予測
テストデータを予測し、expを適用し元に戻します。
y_test_pred = model_lasso.predict(X_test) y_test_pred = np.exp(y_test_pred)-1
提出ファイル「submission.csv」を作成
submission = pd.DataFrame({"Id": test["Id"],"SalePrice": y_test_pred})
submission.loc[submission['SalePrice'] <= 0, 'SalePrice'] = 0
fileName = "submission.csv"
submission.to_csv(fileName, index=False)
あとは、outputタブを開き、「Submit to Competition」ボタンを押すと、ファイルがサブミットされ、Score計算が行われ、結果がLeader board上で表示されます。