‘PostgreSQL’ カテゴリーのアーカイブ
PostgreSQLのTRIGGER備忘録
- 2020/10/20
- aikawa
PostgreSQLのちょっとしたサンプルに便利(そう)なElephantSQL
- 2020/07/09
- murave
- ElephantSQL
以前ElephantSQL(https://www.elephantsql.com/)がちょっとしたサンプルに使うのに便利そうだなと思ったのですが、思い出せなくてモヤモヤしたり社内Slackに書いたはず〜と検索したりしたのでメモっておきます。
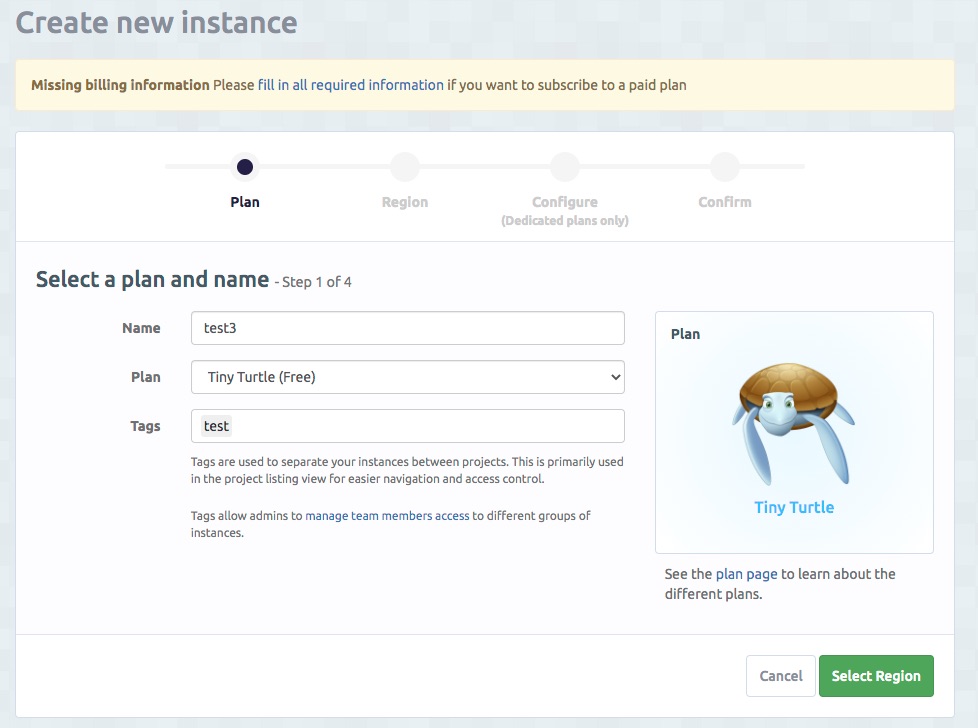
Pricing(https://www.elephantsql.com/plans.html)を見ていただければわかりますが、Tiny Turtle というFREEプランがあるんですよ。データが最大20MBで5同時接続までですけど。
子亀ちゃん、作っていきましょう。
再帰的問い合わせで、複数点間の経路的な使い方
- 2018/12/28
- aikawa
少しだけ時間が出来たので、以前使おうか迷っていたPostgreSQLのWITH RECURSIVEを使って複数点間の移動経路と距離を求めるようなSQLを作ってみました。
※使おうと思ってた箇所は、計算Costが問題になりそうだったので、結局group化する列を追加して対応しましたが。
Laravel 5.5 でデータベースdumpをお手軽にとったりもどしたり
- 2017/11/27
- murave
- Laravel
- PostgreSQL
muraveです。LTSを使いたい人なのでLaravelのバージョンが5.1から5.5にジャンプアップしました。
その際、いままで使っていたデータベースバックアップのプラグインが使えなくなりました。
データベースdumpをお手軽にとったりもどしたりしたかっただけだったんだけど、重厚なバックアップ用パッケージが見つかった。これはこれで入れとくかぁ。
— murave (@murave) 2017年11月24日
ということで
https://github.com/spatie/laravel-backup
を導入。良い感じです。もしかして?と、この方のリポジトリを探してみたらありました。
https://github.com/spatie/laravel-db-snapshots
This package provides Artisan commands to quickly dump and load databases in a Laravel application.
そうそう、この記事の対象データベースはPostgreSQLです。
PostgreSQLの場合にレストア時にエラーでデータベースを飛ばしたので、その対処方法のメモだったりします。MySQL、SQLiteにも対応らしいですが試してません。導入や使い方はドキュメント見てくださいね。
CentOS7のPostgreSQL9.2で全文検索
- 2017/01/27
- aikawa
PostgreSQLの全文検索でLudia, textsearch_sennaを使っていたのですが、9.2ではどちらも使えないので、代替となりそうなものを探した結果、pg_trgm, pg_bigm, textsearch_jaの三つが使えそうでした。
ただpg_trgmは日本語を使うにはソースからのコンパイルが必要で、しかも二文字以下は使えないのでパスしました。
Docker公式イメージで開発用RDBをゲットだぜ(PostgreSQL編)
- 2016/08/16
- murave
- Docker
- PostgreSQL
まえがき
Laravelでの開発時にデプロイ先はMySQLなのに手を抜いて手元の開発機ではSQLiteを使っていたら痛い目にあったりしました、muraveです。
SQLiteって結構ルーズにつかえてしまうので手元の開発でSQLite使っててMySQL運用のサーバーにデプロイするとエラーがバンバンというのが昨日から連続発生中。
— murave (@murave) 2016年7月14日
開発環境にあまり影響を与えずにサクッと開発用のRDB(Relational Database)を建てられると素敵ですね。Docker公式イメージを活用すると出来そうです。
RDBというデッカイ単語を使っていますが、自分がよく使うPostgreSQL、MySQL、MariaDBなどについて調べようと思います。MySQLとMariaDB自体はほぼ同じ扱い方ができるRDBですが、公式イメージでの扱いはどうなんでしょうね。
記事にまとめながら試していこうと思います。Docker for Macを使用しており、今回はPostgreSQLです。
お気楽スロークエリ(JOIN & GROUP編)
- 2016/05/10
- murave
- PostgreSQL
- SQL
運用中の業務系システムがあるんですが、お客様から「遅い」とご指摘を頂いた機能を調べたところ台帳からデータを取得し、集計しているクエリが非常に遅い事が判明しました。
調査している環境のデータベースは PostgreSQL 9.3 です。こんな時は EXPLAIN ANALYZE。
phpenv で入れた PHP に pdo_pgsql をインストール
- 2014/08/23
- murave
実際は前の記事の前にやったんですけど、動かしたいソフトが使っていたのはpdo_pgsqlじゃなかったのでありました。
ということで、環境は前の記事と同じでPostgres.appを使用しててPostgreSQLのバージョンは9.3.5.0。対象のPHPのバージョンは5.5.14です。anyenvもからんでいるのでphpenv単独の場合とは少しディレクトリ構成が違う点にご注意ください。
以下の記事を参考に作業しました。
まずはpeclのサイトからpdo_pgsqlを取ってきて解凍。
$ cd tmp
$ wget http://pecl.php.net/get/PDO_PGSQL-1.0.2.tgz
$ tar zxvf PDO_PGSQL-1.0.2.tgz
$ cd PDO_PGSQL-1.0.2
ぺちぱいず(読み方不明)だ!
$ phpize
こんふぃぎゅあしてめいくしましょう。
$ ./configure --with-pdo-pgsql=/Applications/Postgres.app/Contents/Versions/9.3/bin
$ make
インストール内容を確認してから
$ make test
インストール。
$ make install
有効化するためにpdo_pgsqのためのiniファイルを作成。
$ vim /Users/murave/.anyenv/envs/phpenv/versions/5.5.14/etc/conf.d/pdo_pgsql.ini
内容。
extension=pdo_pgsql.so
php.iniに直接追加してもいいけどphp.iniがリセットされて泣いたりするかもしれないから分けておくといいと思う(経験者)。
確認。
$ php -i | grep pdo_pgsql
![]()
![]()
![]()
![]()
![]()
phpenv + php-build で php_pgsql を有効化したPHPをインストール
- 2014/08/22
- murave
開発環境のMacでPHPからPostgreSQLにアクセスできなくてアレレ〜となったので入れなおしました。その際のメモをまとめておきます。
Postgres.appを使用しており、PostgreSQLのバージョンは9.3.5.0です。
インストールしたPHPのバージョンは5.5.14。
anyenvもからんでいるのでphpenv単独の場合とは少しディレクトリ構成が違う点にご注意ください。
php_pgsqlを有効にするためにconfigure_optionを追加します。
$ vim /Users/murave/.anyenv/envs/phpenv/share/php-build/definitions/5.5.14
編集します。
configure_option "--with-pgsql" "/Applications/Postgres.app/Contents/Versions/9.3/bin"
install_package "http://php.net/distributions/php-5.5.14.tar.bz2"
install_pyrus
install_xdebug "2.2.5"
enable_builtin_opcache
configure_option “–with-pgsql” の行を追加しました。ここはPostgreSQLの導入状況にあわせる必要があります。
インストールします。
$ phpenv install 5.5.14
インストールしたPHPに切り替えて確認。
$ phpenv global 5.5.14
$ phpenv rehash
$ php -i | grep pgsql
![]()
![]()
![]()
![]()
![]()
OpenCOBOLとファイル操作(弊社拡張)
OpenCOBOLからのファイル操作ですが内部での定義によって幾つか種類があります。
- 固定長レコードのシーケンシャルファイル
- 固定長レコードのISAM形式ファイル
- 可変長レコードのシーケンシャルファイル
- 他
これらはCOBOLソース内でのSELECT句での定義でファイル名を直接または環境変数を経由して間接的に指定することが可能です。OpenCOBOLの素の状態ですと
SELECT ADBF0320 ASSIGN TO "FILE0001"
ORGANIZATION SEQUENTIAL
ACCESS MODE SEQUENTIAL.
と記述されている場合は、FILE0001または環境変数 DD_FILE0001または dd_FILE0001に設定されているファイル名のファイルのOPENが可能です。弊社ではこの環境変数渡しの機能を活用してperlからOpenCOBOL側へJCL中で使用しているファイル名を渡しています。
さて、JCL中ではSYSINと呼ばれる形式でファイルを作らずにその場で渡したいデータを記述することがあります。
\INPUT ACCEPT1,TYPE=DATASSF,LIST=YES
4241122 登録データ1
4241122 登録データ1追加分
\ENDINPUT;
ADAM2200:
\STEP PROG2000 FILE=USL.CAT1 DUMP=DATA SUBLM=NORMAL;
\ASSIGN FILE0010 USR.F001 SHARE=ALL HOLDMODE=NO;
\ASSIGN FILE0110 USR.F011-T FILESTAT=TEMP PUBLIC NORMAL=PASS;
\ALLOCATE FILE0110 USR.F011-T SIZE=05;
\DEFINE FILE0110 RECSIZE=57 BLOCKSZ=10260 INCRSZ=01
RELSP RECFORM=FB;
\ASSIGN SIN ACCEPT1 FILESTAT=SYSIN;
\ENDSTEP;
上記ではJCL中で定義されたASSIGN1というSYSINの内容をSINというファイル識別名に割り当てています。これをperlに置き換える(この部分自動的に処理しています)と
INPUT "ACCEPT1,TYPE=DATASSF,LIST=YES",<<_EOT;
4241122 登録データ1
4241123 登録データ1追加分
_EOT
ENDINPUT;
ADAM2200:
STEP "PROG2000 FILE=USL.CAT1 DUMP=DATA SUBLM=NORMAL";
ASSIGN "FILE0010 USR.F001 SHARE=ALL HOLDMODE=NO";
ASSIGN "FILE0110 USR.F011-T FILESTAT=TEMP PUBLIC NORMAL=PASS";
ALLOCATE "FILE0110 USR.F011-T SIZE=05";
DEFINE "FILE0110 RECSIZE=57 BLOCKSZ=10260 INCRSZ=01",
"RELSP RECFORM=FB";
ASSIGN "SIN ACCEPT1 FILESTAT=SYSIN";
上記のように変換しています。さて、SYSINの内容ですがまず1レコードが何byteであるという情報がありません。そして1行毎に行の長さが異なっています。今回移植の対象となった対象機のCOBOLではこのような場合には「改行区切りで1レコード」とするようになっていました。つまり可変長レコードです。ところがOpenCOBOLで可変長レコードをファイルとして扱うためには:
レコード先頭1バイトまたは2バイトにレコード長+1レコード分のデータ
レコード先頭1バイトまたは2バイトにレコード長+1レコード分のデータ
・・・
という形式でデータを作成する必要があります(つまり1byte目がレコード長として正しくないと、メモリ上に過大な長さのデータが読み込まれて、あっという間にSegfault します)。OpenCOBOLの外側からファイルの形式について何らかの方法で指示を出す必要が在りましたので、弊社ではファイル名の先頭に「sysin://」という識別子を(URI的に)付けてファイル名を渡すようにしています。これをOpenCOBOL内のファイルハンドラに渡る前に処理し、改行区切りの可変長レコードとして処理しています。同じく、印刷用の中間データなど1行の長さが可変長となる場合について「sysout://」という識別子を付けて指定することができるようにしています。他、標準の固定長レコードのドライバと動作をちょっと変えたドライバを使いたい場合を考え「misam://」や「mseq://」さらにLinux他では/dev/nullに該当するものとして「nullfs://」という識別子を指定可能としています。
標準の固定長レコードのドライバと動作をちょっと変えたいというのは例えばレコード挿入、削除時の細かい振る舞い、二次キー指定時の動作、二次キーを持っているISAMファイルを主キーしか定義していないCOBOLソースから書き込みモードで開いた場合の動作(OpeCOBOLの標準の動作では、書き込みモードでISAMファイルを開くと、一旦削除されますので、最悪二次キーについての定義が欠落します)等々です。
また、「perlfs://CLASSNAME/param」という形式でファイル名を渡す事によりファイルハンドラとしてperlにて記述したものを呼び出すようにもしています。DBとCOBOL内の固定長レコードの編集用コードについてperlで記述できるため、大変柔軟にDBとの連携を図れるようになりました(つまり、DBD::PgやDBD:MySQL、Oracleなどとの連携も可能です。MySQLについては既に運用されていますし、KeyValue系のDBへの接続もそれほどの変更なしに実装できます)。
上記に加え、固定長レコードやキー定義などの情報を別ディレクトリ内の管理ファイルに登録しておくことで、ファイルオープン時に正しい形式のファイルを使用しているかどうかCOBOLプログラム内の定義と照らし合わせて動的にチェックできるようになり、また現在どのようなファイルがオープン状態であるか?を全てモニタできるようにしています。
これらの改造はOpenCOBOLがオープンソースとして配布されていたことで可能になりました。成果は随時コミュニティ等にフィードバックしていきたいと考えております。
![]()
![]()
![]()
![]()
![]()